ヒトエクソームシーケンス

既知の疾患関連変異の大部分はヒトゲノムのタンパク質コード領域に存在します。ヒトエクソームシーケンスはコード領域だけをターゲットにし、ヒト全ゲノムよりも費用対効果の高い方法です。単一遺伝子疾患、複雑な疾患、がん研究もしくは人口学においても、高品質なデータをお約束します。
データ解析には以下の内容が含まれます。・データQC・参照ゲノム配列へのアライメント・SNP/lnDelの検出・発がん部位と体細胞の異なるSNP/lnDelの検出・統計とアノテーションです。
解析にはBWA、SAMtools、GATKなど世界的に認知度の高いソフトウェアを使用します。
バイオインフォマティクス解析はExome Aggregation Consortium(ExAC)でアノテーションします。ExACデータベースは、色々なゲノムプロジェクトのデータを統合し、60,706名の個人ゲノムデータがあります。このような大人数規模のデータベースは、病因の研究を大いに促進します。
サービスの強み
- 最高水準のエクソンキャプチャー
- アジレントSureSelect Human All Exome V6 (58 M)/V5 (50 M)キットを使用します。
- 最高品質のデータ
- Q30 ≧ 80%はイルミナ社のオフィシャルガイドライン(Q30 ≧ 75%)を上回ります。
- 150bpのリード長
- 正確な変異検出が可能です。
- 最高のバイオインフォマティクス解析
- 最先端のバイオインフォマティクスのプロセスと、世界的に認知度の高いソフトウェアにより、すぐ発表できるデータをお客様に届けます。
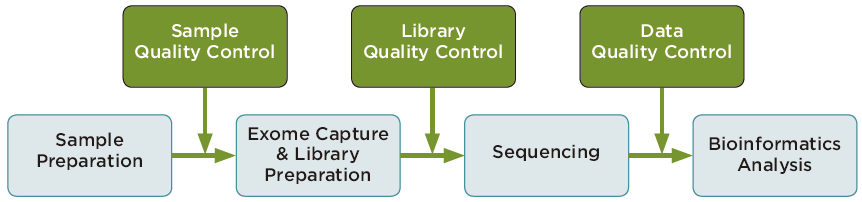
サービスの流れ
- SEQUENCING STRATEGY
- 180 ~ 280 bp insert DNA library
- HiSeq platform, paired-end 150 bp
- DATA QUALITY GUARANTEE
- We guarantee that ≧ 80% of bases have a sequencing quality score ≧ Q30, which exceeds Illumina’s official guarantee of ≧ 75%
- TURNAROUND TIME
- 22 working days after verification of quality (without data analysis)
- Additional 5 working days for data analysis
- RECOMMENDED SEQUENCING DEPTH
- For Mendelian disorder/rare disease:effective sequencing depth above 50x
- For tumor sample: effective sequencing depth above 100x
- SAMPLE REQUIREMENTS
- Input DNA:-For fresh sample: ≧ 1.0 μg (a minimum of 200 ng can be accepted with risk) -For FFPE sample: ≧ 1.5 μg
- DNA concentration: ≧ 20 ng/μl
- DNA Volume: ≧ 10 μl
- OD260/280 = 1.8 - 2.0 without degradation or RNA contamination
- EXOME CAPTURE
- Agilent SureSelect Human All Exon V5/V6 Kit
- ヒトゲノム
- 全ゲノムシーケンス
- 全エクソームシーケンス
- 遺伝子制御
- RNA-seq(mRNA / LncRNA)
- メチル化DNA解析
- ChIP-seq
- 動植物ゲノム
- de novoシーケンス
- リシーケンス